9 Crucial System Design Interview Questions for 2025

The system design interview is more than a technical hurdle; it's a window into how you think, solve problems at scale, and architect resilient systems. For aspiring software engineers and architects, mastering this stage is non-negotiable. It is where you prove you can build for the future, not just code for the present. This guide breaks down 9 of the most revealing system design interview questions you'll face.
We move beyond simple answers, providing a strategic framework, key architectural components to highlight, and common pitfalls to avoid for each question. This isn't just a list; it's a playbook designed to help you demonstrate the senior-level thinking that top companies demand. You’ll learn how to dissect requirements, manage trade-offs, and design for scalability and fault tolerance.
As you prepare, remember that a complete design often involves integrating multiple microservices and protecting them from abuse. Delving deeper into crucial sub-topics like mastering API rate limiting can significantly strengthen your answers, ensuring your proposed systems are robust and practical. Let's dive into the questions that will define your next career move.
1. Design a URL Shortener (like bit.ly or TinyURL)
This is a classic for a reason. Designing a URL shortener like bit.ly seems simple on the surface, but it quickly reveals your understanding of core distributed systems principles. Interviewers use this problem to test your ability to handle massive scale, design a robust data model, and think through critical trade-offs between availability and consistency. It’s a foundational question that covers the full system design lifecycle.
The system must ingest a long URL and generate a unique, short alias. When a user accesses the short URL, the service must redirect them to the original long URL with minimal latency. This read-heavy system requires a thoughtful approach to data storage, caching, and traffic management.
Key Discussion Points
- Requirements & Scale Estimation: Start by clarifying functional requirements (create short URL, redirect) and non-functional requirements (high availability, low latency). Estimate traffic (e.g., 100 million writes/day, 1 billion reads/day) to guide your design choices.
- Short URL Generation: The core of the problem. A common approach is to use a unique, incrementing counter and convert it to a base62 encoding (
[0-9, a-z, A-Z]). This creates short, non-sequential, and URL-safe keys. - Data Storage: Discuss the pros and cons of SQL vs. NoSQL. A NoSQL database like DynamoDB or Cassandra is often preferred for its horizontal scalability and fast key-value lookups, which is perfect for mapping
short_urltolong_url. - System Architecture: A high-level design would include a load balancer distributing requests to a cluster of web servers. These servers communicate with a key-generation service and the database.
Pro Tip: Don't forget to implement a robust caching layer. Using a distributed cache like Redis to store mappings for frequently accessed URLs ("hot" URLs) will dramatically reduce database load and improve redirect latency. Also, discuss adding a Content Delivery Network (CDN) to serve redirects from edge locations closer to the user.
2. Design a Chat System (like WhatsApp or Slack)
This is a frequently asked question in system design interviews because it tests your ability to design a complex, real-time, and highly concurrent system. Building a service like WhatsApp or Slack involves managing persistent connections, ensuring message delivery, and handling user presence at a massive scale. Interviewers use this problem to evaluate your knowledge of WebSockets, message queues, and distributed databases.
The system needs to support one-on-one and group messaging, deliver messages with low latency, and indicate user online/offline status. The design must be horizontally scalable to support millions of active users and guarantee that messages are not lost, even if a user is temporarily offline.
Key Discussion Points
- Requirements & Scale Estimation: Define functional requirements like 1-on-1 chat, group chat, message history, and online presence indicators. Estimate the number of daily active users and messages sent per second to plan for the required infrastructure.
- Connection Management: The core challenge is maintaining persistent connections. WebSockets are the ideal choice over traditional HTTP polling for enabling full-duplex communication between the client and server. Discuss how to manage millions of concurrent WebSocket connections and handle server failover without dropping active sessions.
- Message Flow & Storage: A typical architecture involves clients connecting to chat servers via a load balancer. When a message is sent, the server pushes it to a message queue (like RabbitMQ or Kafka) for asynchronous processing and delivery. For storage, a NoSQL database like Cassandra is excellent for handling time-series message data due to its write performance and scalability.
- User Presence: Explain how to build a presence system. Each user's connection status can be managed by a dedicated service that tracks active connections. When a user connects or disconnects, this service updates their status and notifies their contacts.
Pro Tip: Focus on message delivery guarantees. Discuss the difference between "at least once" and "exactly once" delivery. A common strategy is to use message queues for durability and have clients send acknowledgments (ACKs) back to the server upon receiving a message. This ensures that messages sent while a user is offline can be stored and delivered once they reconnect.
3. Design a Social Media Feed (like Twitter Timeline or Facebook News Feed)
This is one of the most comprehensive system design interview questions, used by companies like Meta and Twitter to gauge your ability to build large-scale, read-heavy systems. It tests your knowledge of data modeling, caching strategies, and the critical trade-offs between different architectural patterns. Interviewers want to see how you handle complex requirements like real-time updates and personalization for millions of users.
The core task is to design a system that aggregates content from various sources (e.g., users you follow) and displays it in a personalized timeline. The system must be highly available and deliver the feed with low latency, balancing the need to show both recent and relevant content. This problem forces you to consider how to efficiently serve a massive number of read requests while ingesting a constant stream of new data.
The infographic below summarizes key architectural decisions in feed design, including fanout models and performance metrics.
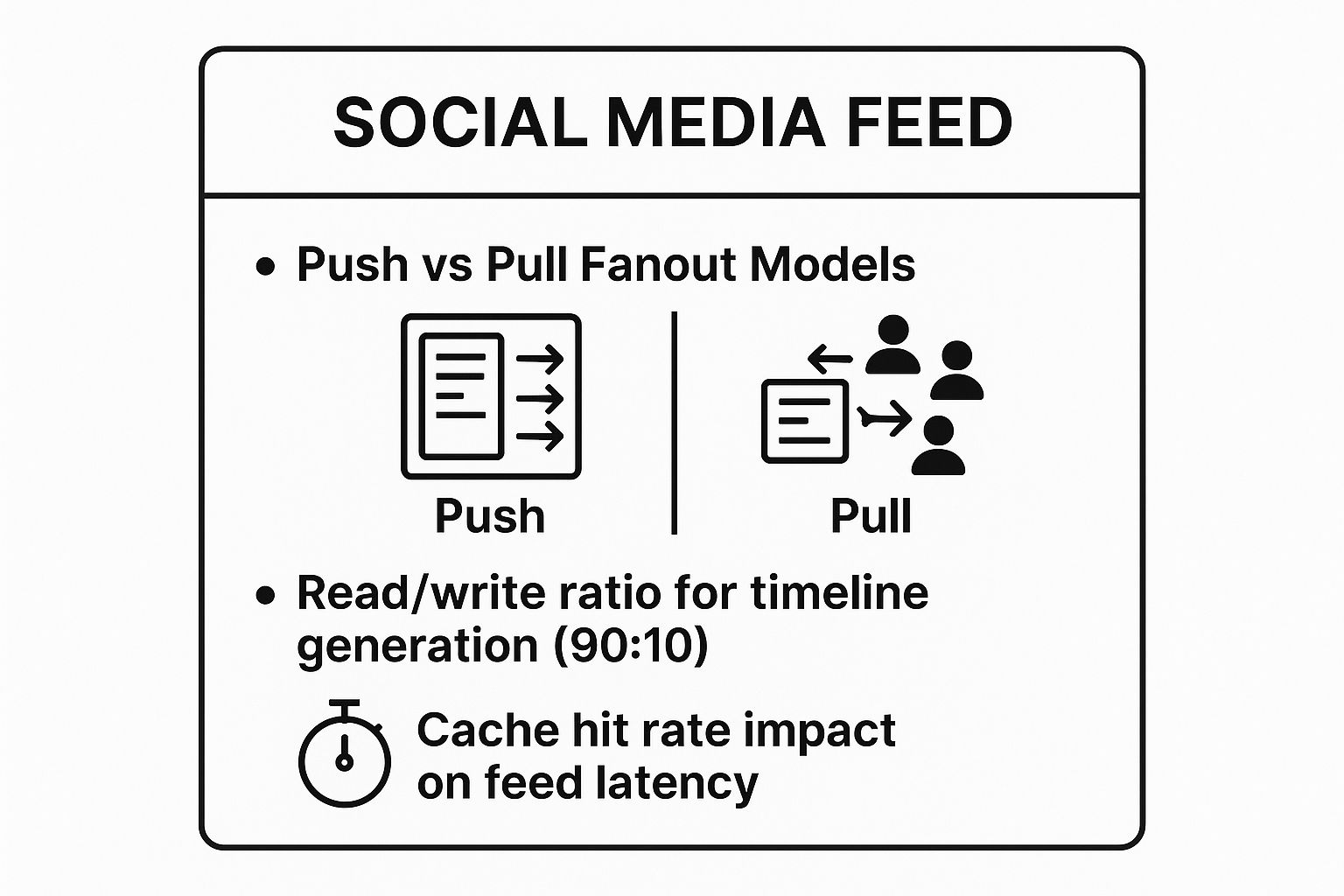
This quick reference highlights the fundamental trade-off between the "push" and "pull" models, a central point of discussion for this problem.
Key Discussion Points
- Requirements & Feed Type: Clarify if the feed is chronological or ranked by an algorithm. Also, distinguish between the home timeline (content from followed users) and the user timeline (a user's own posts).
- Push (Fanout-on-Write): When a user posts, the system pre-computes the timelines for all their followers. This leads to fast read times but can be resource-intensive for users with millions of followers (the "celebrity problem").
- Pull (Fanout-on-Read): The user's feed is generated on demand by fetching posts from everyone they follow. This is simpler to implement but can result in high latency for users who follow many people.
Pro Tip: Propose a hybrid fanout solution to handle the "celebrity problem." For regular users, use the push model. For celebrities, don't pre-compute feeds; instead, fetch their posts and merge them into a user's timeline at read time. Also, discuss using a dedicated caching layer for the generated feeds to ensure sub-second load times.
4. Design a Video Streaming Platform (like YouTube or Netflix)
This is a comprehensive, large-scale design problem that tests your ability to think about complex, asynchronous pipelines and global content distribution. Interviewers use this question to assess your understanding of handling large binary files (videos), Content Delivery Networks (CDNs), and the trade-offs involved in delivering a high-quality user experience across varying network conditions. It's a fantastic problem for showcasing your grasp of end-to-end system architecture.
The core challenge is to design a system that can ingest user-uploaded videos, process them into multiple formats, and stream them efficiently to millions of concurrent users worldwide. This involves separating the video upload and processing workflow (write path) from the video delivery workflow (read path), as they have vastly different requirements.
Key Discussion Points
- System Architecture (Upload vs. Stream): A key design choice is to decouple the two main workflows. The upload pipeline involves a web server, a message queue (like Kafka or RabbitMQ) for processing jobs, and a fleet of worker services for transcoding. The streaming pipeline is read-heavy, focusing on a global CDN and efficient metadata retrieval.
- Video Processing Pipeline: Once a video is uploaded to raw storage (like Amazon S3), a message is sent to a queue. Worker nodes pick up the job and perform transcoding - converting the video into different resolutions and formats (e.g., 1080p, 720p, 480p) using codecs like H.264. This enables adaptive bitrate streaming.
- Storage & CDN: Discuss storage solutions. Original files can go into cheaper object storage (e.g., S3 Standard), while processed, streamable video segments are stored in a more accessible tier and pushed to a CDN. The CDN is critical for low-latency streaming by caching content at edge locations close to users.
- Data Model: The database (often a combination of SQL for user data and NoSQL for video metadata like views, comments, and tags) needs to support fast lookups. The metadata service will provide the client with a manifest file listing available video segments and their CDN URLs.
Pro Tip: Focus on adaptive bitrate streaming. Explain how a video player client dynamically requests different quality chunks (e.g., 1080p vs. 480p) based on the user's current network bandwidth. This is fundamental to providing a smooth playback experience without buffering, making it a critical aspect of modern video streaming system design interview questions.
5. Design a Search Engine (like Google)
This is one of the most comprehensive and challenging system design interview questions you can face. Designing a search engine like Google tests your understanding of the entire data pipeline, from large-scale data ingestion (crawling) and processing (indexing) to real-time, low-latency querying. Interviewers use this problem to gauge your ability to break down a colossal system into manageable components and design for extreme scale.
The system must crawl billions of web pages, process and index their content, and serve relevant, ranked search results to users in milliseconds. This involves a complex interplay between distributed crawlers, a massive data processing pipeline, and a highly available query service. It is a fantastic question for demonstrating deep knowledge of distributed systems.
Key Discussion Points
- System Components: Break the system into three core parts: a Web Crawler (to fetch web pages), an Indexer (to create a searchable data structure), and a Query Engine (to retrieve and rank results). Discussing the high-level architecture of these components is a great starting point.
- Indexing: The cornerstone of any search engine is the inverted index. Explain how you would map words (tokens) to the documents that contain them. Discuss how to store this massive index, likely using a distributed, sharded database like Bigtable or a custom file-based system on a distributed filesystem like HDFS.
- Ranking: How do you determine which results are most relevant? Briefly touch upon ranking algorithms like PageRank (link analysis) and other signals like term frequency (TF-IDF) and user location. Acknowledging the complexity of modern ranking is key.
- Scalability & Performance: Address how to scale each component. Crawlers can be distributed, index building can be done via MapReduce jobs, and the query engine requires sharding the index across many servers so that queries can be processed in parallel.
Pro Tip: Don't try to design all of Google in 45 minutes. Instead, scope the problem down. You might say, "Let's focus on the indexing pipeline first," or "Let's assume the index is built and focus on the query serving part." This shows the interviewer you can manage complexity and prioritize. Also, mention caching query results to handle popular searches efficiently.
6. Design a Ride-Sharing Service (like Uber or Lyft)
This question dives deep into real-time, location-based systems. Designing a service like Uber or Lyft challenges you to think about handling massive streams of dynamic data, efficient matching algorithms, and state management for millions of concurrent trips. Interviewers use this problem to assess your grasp of geospatial indexing, real-time communication protocols, and building a fault-tolerant, mobile-first architecture.
The core of the system involves matching riders seeking a trip with nearby available drivers. This requires constantly ingesting location updates from both parties, running a matching algorithm to find the optimal driver, managing the lifecycle of the trip from request to completion, and handling payments. It’s a complex interplay between availability, consistency, and low-latency communication.
Key Discussion Points
- Requirements & Scale Estimation: Clarify core features like requesting a ride, driver matching, real-time tracking, and payments. Estimate the number of active users and drivers (e.g., 1 million concurrent drivers, 10 million active riders) to scope the services needed.
- Geospatial Indexing: The critical component for finding nearby drivers. Discuss using geohashing or quadtrees to partition the world into a grid. This allows for efficient querying of drivers within a specific geographic area, avoiding a slow, full database scan.
- System Architecture: A high-level design would involve a "Driver Location Service" that ingests location updates and a "Matching Service" that pairs riders and drivers. Use a message queue like Kafka to handle the high volume of location pings from mobile clients.
- Real-Time Communication: For live tracking, a persistent connection is more efficient than constant HTTP polling. Discuss using WebSockets or MQTT to push driver location updates to the rider's app and trip status changes to both parties.
Pro Tip: Don't overlook trip state management. A trip has multiple states (requested, accepted, in-progress, completed, canceled). Use a state machine and a reliable database to manage these transitions consistently. Also, discuss how to implement surge pricing by analyzing supply and demand in specific geographic regions.
7. Design a Distributed Cache System (like Redis or Memcached)
This advanced system design interview question moves beyond using a cache as a component and asks you to build the cache itself. Interviewers present this problem to probe your deep understanding of data structures, networking, concurrency, and distributed systems concepts. It tests your ability to manage trade-offs between performance, consistency, and fault tolerance in a high-throughput, low-latency environment.
The system must provide a simple API for setting and getting key-value pairs with high availability and minimal latency. It needs to operate in a distributed cluster, handling node failures gracefully and partitioning data effectively across the network. Designing a system like Redis or Memcached requires a focus on in-memory storage, efficient eviction policies, and cluster management.
Key Discussion Points
- Requirements & Scale Estimation: Define core operations (GET, SET, DELETE) and non-functional requirements like sub-millisecond latency and high availability (e.g., 99.99%). Estimate the data size (e.g., 1 TB of cacheable data) and request rate (e.g., 10 million QPS) to determine the number of nodes required.
- Data Partitioning: Consistent hashing is the critical concept here. Explain how it minimizes data reshuffling when nodes are added or removed, which is essential for maintaining cache performance and availability during scaling events.
- Cache Eviction Policies: Memory is finite, so a strategy for removing old or less-used data is crucial. Discuss common policies like Least Recently Used (LRU), Least Frequently Used (LFU), and First-In-First-Out (FIFO), and justify your choice based on the expected access patterns.
- Consistency & Replication: How does the system handle writes and ensure data is replicated for fault tolerance? Discuss replication strategies (e.g., primary-backup) and consistency models (e.g., eventual vs. strong consistency) and their impact on performance and reliability.
Pro Tip: Go deeper by discussing failure detection and node recovery. How does the cluster know a node is down? A heartbeat mechanism is a common solution. Also, consider cache coherence challenges: if the source of truth (a database) is updated, how is the stale data in the cache invalidated or updated? This demonstrates a complete understanding of the cache's role in a larger architecture.
8. Design a Notification System (Push Notifications, Email, SMS)
This problem explores your ability to design a high-throughput, reliable, and scalable system that handles diverse communication channels. Interviewers use this question to evaluate your understanding of asynchronous processing, message queues, third-party API integration, and fault tolerance. It’s a practical problem that mirrors real-world engineering challenges at companies like Meta, Google, or any large-scale platform.
The system needs to accept notification requests, process them, and dispatch them via multiple channels like push notifications (APNS, FCM), SMS (Twilio), and email (SendGrid). It must be resilient to third-party service failures, support scheduling, handle retries, and manage user preferences, making it a comprehensive test of your system design interview skills.
Key Discussion Points
- Requirements & Scale Estimation: Clarify functional requirements (send notifications, schedule delivery, track status) and non-functional ones (high availability, reliability, low latency). Estimate the volume, such as 10 million notifications per hour, to justify choices like using a message queue.
- System Architecture: A robust design involves multiple microservices. An API Gateway receives requests and sends them to a Notification Service. This service validates the request, enriches it with user data, and publishes it to a Message Queue like Kafka or RabbitMQ.
- Decoupled Delivery Services: Downstream, have separate worker services for each channel (Push, SMS, Email). Each service consumes messages from the queue, formats the content using a template system, and communicates with the relevant third-party provider (e.g., APNS, Twilio). This decoupling prevents a single provider's failure from halting the entire system.
- Reliability and Tracking: Discuss implementing a retry mechanism with exponential backoff for failed deliveries. A separate Tracking Service should handle delivery status callbacks from providers to update the notification's state (sent, delivered, failed) in a database.
Pro Tip: A critical component is the Message Queue. It acts as a buffer, decoupling the ingestion of notification requests from the actual sending process. This makes the system resilient to traffic spikes and downstream service failures, ensuring no notification is lost even if a third-party API is temporarily unavailable. Also, mention implementing rate limiting to respect provider limits and avoid being flagged as spam.
9. Design a Distributed File Storage System (like Google Drive or Dropbox)
This question challenges you to build one of the most complex yet common applications used today. Designing a system like Dropbox or Google Drive goes beyond simple storage; it tests your knowledge of data synchronization, conflict resolution, distributed file systems, and large-scale data management. Interviewers use it to gauge your ability to design for reliability, consistency, and efficiency when handling user data.
The core task is to allow users to upload, store, and access files from anywhere, on any device. The system must keep files synchronized in near real-time, manage file versions, handle sharing permissions, and support offline access. It is a write-heavy system during uploads and syncs but must also provide low-latency reads.
Key Discussion Points
- Client-Side Architecture: The design starts on the user's device. A client application must monitor a local folder for changes (create, update, delete). It needs to break large files into smaller, manageable chunks for efficient uploads and downloads.
- Synchronization Service: This is the brain of the operation. The client communicates with a central synchronization service to report changes and receive updates from other clients. This service manages file metadata and coordinates the data transfer process.
- Metadata vs. Block Storage: A crucial design choice is separating metadata (file names, versions, permissions, chunk locations) from the actual file content (the chunks). Metadata can be stored in a scalable SQL or NoSQL database, while the file chunks are stored in a distributed object store like Amazon S3.
- Conflict Resolution: What happens if a user edits the same file on two different offline devices? You must design a strategy for handling conflicts. A common approach is to save both versions and notify the user to resolve the conflict manually (e.g., "Conflicted Copy").
Pro Tip: Discuss advanced optimizations like delta syncing and deduplication. Instead of re-uploading an entire file when only a small part changes, delta sync sends only the modified chunks. Deduplication at the chunk level saves immense storage space by storing a single copy of identical chunks across the entire system.
System Design Interview Questions Comparison
Your Next Step: From Theory to Interview Success
You’ve just navigated the architectural blueprints behind some of the most challenging and common system design interview questions. From designing a nimble URL shortener to a globally scaled video streaming platform, you now have a foundational understanding of the core components, trade-offs, and design patterns that interviewers are looking for. The journey through designing news feeds, chat systems, and distributed caches isn't just an academic exercise; it’s a direct reflection of the real-world problems you will be expected to solve as a senior engineer.
The key takeaway is that there is rarely a single "correct" answer. Instead, success lies in your ability to navigate ambiguity, justify your decisions, and articulate a clear, structured thought process. Remember the recurring themes we explored:
- Scalability: Always start with a simple design and discuss how to scale it horizontally and vertically.
- Availability and Reliability: Incorporate redundancy, load balancing, and failover mechanisms from the start.
- Latency: Understand the bottlenecks and employ strategies like caching, CDNs, and choosing the right database to optimize for speed.
- Trade-offs: Every decision, from a database choice to a consistency model, has consequences. Your ability to weigh these pros and cons is what truly demonstrates seniority.
Turning Knowledge into Confidence
Reading about these systems is the first step, but the real test is applying this knowledge under pressure. The gap between knowing the theory of CAP theorem and explaining its implications for a specific database choice in a live interview can be significant. This is where deliberate, targeted practice becomes your greatest asset.
Start by whiteboarding these problems on your own. Talk through your design out loud, as if you were explaining it to an interviewer. This helps solidify the concepts and reveals gaps in your understanding. Consider how the context might change if the interview is for a remote position. The ability to communicate complex technical ideas clearly over video is a critical skill, so be sure to also review common remote job interview questions that often arise in the virtual hiring process.
Ultimately, your goal is to build muscle memory not just for the technical solutions, but for the communication framework itself. You want to walk into that room, virtual or physical, with a clear plan for how to tackle any open-ended design prompt thrown your way. By combining the deep architectural knowledge from this guide with consistent, focused practice, you transform preparation from a chore into a source of confidence. You aren't just memorizing answers; you are becoming the engineer who can build the future.
Ready to bridge the gap between theory and interview-ready performance? AIApply provides a realistic practice environment where you can articulate your designs and receive instant, AI-powered feedback on your communication and technical clarity. Perfect your pitch and build the confidence to ace your next system design interview with AIApply.
The system design interview is more than a technical hurdle; it's a window into how you think, solve problems at scale, and architect resilient systems. For aspiring software engineers and architects, mastering this stage is non-negotiable. It is where you prove you can build for the future, not just code for the present. This guide breaks down 9 of the most revealing system design interview questions you'll face.
We move beyond simple answers, providing a strategic framework, key architectural components to highlight, and common pitfalls to avoid for each question. This isn't just a list; it's a playbook designed to help you demonstrate the senior-level thinking that top companies demand. You’ll learn how to dissect requirements, manage trade-offs, and design for scalability and fault tolerance.
As you prepare, remember that a complete design often involves integrating multiple microservices and protecting them from abuse. Delving deeper into crucial sub-topics like mastering API rate limiting can significantly strengthen your answers, ensuring your proposed systems are robust and practical. Let's dive into the questions that will define your next career move.
1. Design a URL Shortener (like bit.ly or TinyURL)
This is a classic for a reason. Designing a URL shortener like bit.ly seems simple on the surface, but it quickly reveals your understanding of core distributed systems principles. Interviewers use this problem to test your ability to handle massive scale, design a robust data model, and think through critical trade-offs between availability and consistency. It’s a foundational question that covers the full system design lifecycle.
The system must ingest a long URL and generate a unique, short alias. When a user accesses the short URL, the service must redirect them to the original long URL with minimal latency. This read-heavy system requires a thoughtful approach to data storage, caching, and traffic management.
Key Discussion Points
- Requirements & Scale Estimation: Start by clarifying functional requirements (create short URL, redirect) and non-functional requirements (high availability, low latency). Estimate traffic (e.g., 100 million writes/day, 1 billion reads/day) to guide your design choices.
- Short URL Generation: The core of the problem. A common approach is to use a unique, incrementing counter and convert it to a base62 encoding (
[0-9, a-z, A-Z]). This creates short, non-sequential, and URL-safe keys. - Data Storage: Discuss the pros and cons of SQL vs. NoSQL. A NoSQL database like DynamoDB or Cassandra is often preferred for its horizontal scalability and fast key-value lookups, which is perfect for mapping
short_urltolong_url. - System Architecture: A high-level design would include a load balancer distributing requests to a cluster of web servers. These servers communicate with a key-generation service and the database.
Pro Tip: Don't forget to implement a robust caching layer. Using a distributed cache like Redis to store mappings for frequently accessed URLs ("hot" URLs) will dramatically reduce database load and improve redirect latency. Also, discuss adding a Content Delivery Network (CDN) to serve redirects from edge locations closer to the user.
2. Design a Chat System (like WhatsApp or Slack)
This is a frequently asked question in system design interviews because it tests your ability to design a complex, real-time, and highly concurrent system. Building a service like WhatsApp or Slack involves managing persistent connections, ensuring message delivery, and handling user presence at a massive scale. Interviewers use this problem to evaluate your knowledge of WebSockets, message queues, and distributed databases.
The system needs to support one-on-one and group messaging, deliver messages with low latency, and indicate user online/offline status. The design must be horizontally scalable to support millions of active users and guarantee that messages are not lost, even if a user is temporarily offline.
Key Discussion Points
- Requirements & Scale Estimation: Define functional requirements like 1-on-1 chat, group chat, message history, and online presence indicators. Estimate the number of daily active users and messages sent per second to plan for the required infrastructure.
- Connection Management: The core challenge is maintaining persistent connections. WebSockets are the ideal choice over traditional HTTP polling for enabling full-duplex communication between the client and server. Discuss how to manage millions of concurrent WebSocket connections and handle server failover without dropping active sessions.
- Message Flow & Storage: A typical architecture involves clients connecting to chat servers via a load balancer. When a message is sent, the server pushes it to a message queue (like RabbitMQ or Kafka) for asynchronous processing and delivery. For storage, a NoSQL database like Cassandra is excellent for handling time-series message data due to its write performance and scalability.
- User Presence: Explain how to build a presence system. Each user's connection status can be managed by a dedicated service that tracks active connections. When a user connects or disconnects, this service updates their status and notifies their contacts.
Pro Tip: Focus on message delivery guarantees. Discuss the difference between "at least once" and "exactly once" delivery. A common strategy is to use message queues for durability and have clients send acknowledgments (ACKs) back to the server upon receiving a message. This ensures that messages sent while a user is offline can be stored and delivered once they reconnect.
3. Design a Social Media Feed (like Twitter Timeline or Facebook News Feed)
This is one of the most comprehensive system design interview questions, used by companies like Meta and Twitter to gauge your ability to build large-scale, read-heavy systems. It tests your knowledge of data modeling, caching strategies, and the critical trade-offs between different architectural patterns. Interviewers want to see how you handle complex requirements like real-time updates and personalization for millions of users.
The core task is to design a system that aggregates content from various sources (e.g., users you follow) and displays it in a personalized timeline. The system must be highly available and deliver the feed with low latency, balancing the need to show both recent and relevant content. This problem forces you to consider how to efficiently serve a massive number of read requests while ingesting a constant stream of new data.
The infographic below summarizes key architectural decisions in feed design, including fanout models and performance metrics.
This quick reference highlights the fundamental trade-off between the "push" and "pull" models, a central point of discussion for this problem.
Key Discussion Points
- Requirements & Feed Type: Clarify if the feed is chronological or ranked by an algorithm. Also, distinguish between the home timeline (content from followed users) and the user timeline (a user's own posts).
- Push (Fanout-on-Write): When a user posts, the system pre-computes the timelines for all their followers. This leads to fast read times but can be resource-intensive for users with millions of followers (the "celebrity problem").
- Pull (Fanout-on-Read): The user's feed is generated on demand by fetching posts from everyone they follow. This is simpler to implement but can result in high latency for users who follow many people.
Pro Tip: Propose a hybrid fanout solution to handle the "celebrity problem." For regular users, use the push model. For celebrities, don't pre-compute feeds; instead, fetch their posts and merge them into a user's timeline at read time. Also, discuss using a dedicated caching layer for the generated feeds to ensure sub-second load times.
4. Design a Video Streaming Platform (like YouTube or Netflix)
This is a comprehensive, large-scale design problem that tests your ability to think about complex, asynchronous pipelines and global content distribution. Interviewers use this question to assess your understanding of handling large binary files (videos), Content Delivery Networks (CDNs), and the trade-offs involved in delivering a high-quality user experience across varying network conditions. It's a fantastic problem for showcasing your grasp of end-to-end system architecture.
The core challenge is to design a system that can ingest user-uploaded videos, process them into multiple formats, and stream them efficiently to millions of concurrent users worldwide. This involves separating the video upload and processing workflow (write path) from the video delivery workflow (read path), as they have vastly different requirements.
Key Discussion Points
- System Architecture (Upload vs. Stream): A key design choice is to decouple the two main workflows. The upload pipeline involves a web server, a message queue (like Kafka or RabbitMQ) for processing jobs, and a fleet of worker services for transcoding. The streaming pipeline is read-heavy, focusing on a global CDN and efficient metadata retrieval.
- Video Processing Pipeline: Once a video is uploaded to raw storage (like Amazon S3), a message is sent to a queue. Worker nodes pick up the job and perform transcoding - converting the video into different resolutions and formats (e.g., 1080p, 720p, 480p) using codecs like H.264. This enables adaptive bitrate streaming.
- Storage & CDN: Discuss storage solutions. Original files can go into cheaper object storage (e.g., S3 Standard), while processed, streamable video segments are stored in a more accessible tier and pushed to a CDN. The CDN is critical for low-latency streaming by caching content at edge locations close to users.
- Data Model: The database (often a combination of SQL for user data and NoSQL for video metadata like views, comments, and tags) needs to support fast lookups. The metadata service will provide the client with a manifest file listing available video segments and their CDN URLs.
Pro Tip: Focus on adaptive bitrate streaming. Explain how a video player client dynamically requests different quality chunks (e.g., 1080p vs. 480p) based on the user's current network bandwidth. This is fundamental to providing a smooth playback experience without buffering, making it a critical aspect of modern video streaming system design interview questions.
5. Design a Search Engine (like Google)
This is one of the most comprehensive and challenging system design interview questions you can face. Designing a search engine like Google tests your understanding of the entire data pipeline, from large-scale data ingestion (crawling) and processing (indexing) to real-time, low-latency querying. Interviewers use this problem to gauge your ability to break down a colossal system into manageable components and design for extreme scale.
The system must crawl billions of web pages, process and index their content, and serve relevant, ranked search results to users in milliseconds. This involves a complex interplay between distributed crawlers, a massive data processing pipeline, and a highly available query service. It is a fantastic question for demonstrating deep knowledge of distributed systems.
Key Discussion Points
- System Components: Break the system into three core parts: a Web Crawler (to fetch web pages), an Indexer (to create a searchable data structure), and a Query Engine (to retrieve and rank results). Discussing the high-level architecture of these components is a great starting point.
- Indexing: The cornerstone of any search engine is the inverted index. Explain how you would map words (tokens) to the documents that contain them. Discuss how to store this massive index, likely using a distributed, sharded database like Bigtable or a custom file-based system on a distributed filesystem like HDFS.
- Ranking: How do you determine which results are most relevant? Briefly touch upon ranking algorithms like PageRank (link analysis) and other signals like term frequency (TF-IDF) and user location. Acknowledging the complexity of modern ranking is key.
- Scalability & Performance: Address how to scale each component. Crawlers can be distributed, index building can be done via MapReduce jobs, and the query engine requires sharding the index across many servers so that queries can be processed in parallel.
Pro Tip: Don't try to design all of Google in 45 minutes. Instead, scope the problem down. You might say, "Let's focus on the indexing pipeline first," or "Let's assume the index is built and focus on the query serving part." This shows the interviewer you can manage complexity and prioritize. Also, mention caching query results to handle popular searches efficiently.
6. Design a Ride-Sharing Service (like Uber or Lyft)
This question dives deep into real-time, location-based systems. Designing a service like Uber or Lyft challenges you to think about handling massive streams of dynamic data, efficient matching algorithms, and state management for millions of concurrent trips. Interviewers use this problem to assess your grasp of geospatial indexing, real-time communication protocols, and building a fault-tolerant, mobile-first architecture.
The core of the system involves matching riders seeking a trip with nearby available drivers. This requires constantly ingesting location updates from both parties, running a matching algorithm to find the optimal driver, managing the lifecycle of the trip from request to completion, and handling payments. It’s a complex interplay between availability, consistency, and low-latency communication.
Key Discussion Points
- Requirements & Scale Estimation: Clarify core features like requesting a ride, driver matching, real-time tracking, and payments. Estimate the number of active users and drivers (e.g., 1 million concurrent drivers, 10 million active riders) to scope the services needed.
- Geospatial Indexing: The critical component for finding nearby drivers. Discuss using geohashing or quadtrees to partition the world into a grid. This allows for efficient querying of drivers within a specific geographic area, avoiding a slow, full database scan.
- System Architecture: A high-level design would involve a "Driver Location Service" that ingests location updates and a "Matching Service" that pairs riders and drivers. Use a message queue like Kafka to handle the high volume of location pings from mobile clients.
- Real-Time Communication: For live tracking, a persistent connection is more efficient than constant HTTP polling. Discuss using WebSockets or MQTT to push driver location updates to the rider's app and trip status changes to both parties.
Pro Tip: Don't overlook trip state management. A trip has multiple states (requested, accepted, in-progress, completed, canceled). Use a state machine and a reliable database to manage these transitions consistently. Also, discuss how to implement surge pricing by analyzing supply and demand in specific geographic regions.
7. Design a Distributed Cache System (like Redis or Memcached)
This advanced system design interview question moves beyond using a cache as a component and asks you to build the cache itself. Interviewers present this problem to probe your deep understanding of data structures, networking, concurrency, and distributed systems concepts. It tests your ability to manage trade-offs between performance, consistency, and fault tolerance in a high-throughput, low-latency environment.
The system must provide a simple API for setting and getting key-value pairs with high availability and minimal latency. It needs to operate in a distributed cluster, handling node failures gracefully and partitioning data effectively across the network. Designing a system like Redis or Memcached requires a focus on in-memory storage, efficient eviction policies, and cluster management.
Key Discussion Points
- Requirements & Scale Estimation: Define core operations (GET, SET, DELETE) and non-functional requirements like sub-millisecond latency and high availability (e.g., 99.99%). Estimate the data size (e.g., 1 TB of cacheable data) and request rate (e.g., 10 million QPS) to determine the number of nodes required.
- Data Partitioning: Consistent hashing is the critical concept here. Explain how it minimizes data reshuffling when nodes are added or removed, which is essential for maintaining cache performance and availability during scaling events.
- Cache Eviction Policies: Memory is finite, so a strategy for removing old or less-used data is crucial. Discuss common policies like Least Recently Used (LRU), Least Frequently Used (LFU), and First-In-First-Out (FIFO), and justify your choice based on the expected access patterns.
- Consistency & Replication: How does the system handle writes and ensure data is replicated for fault tolerance? Discuss replication strategies (e.g., primary-backup) and consistency models (e.g., eventual vs. strong consistency) and their impact on performance and reliability.
Pro Tip: Go deeper by discussing failure detection and node recovery. How does the cluster know a node is down? A heartbeat mechanism is a common solution. Also, consider cache coherence challenges: if the source of truth (a database) is updated, how is the stale data in the cache invalidated or updated? This demonstrates a complete understanding of the cache's role in a larger architecture.
8. Design a Notification System (Push Notifications, Email, SMS)
This problem explores your ability to design a high-throughput, reliable, and scalable system that handles diverse communication channels. Interviewers use this question to evaluate your understanding of asynchronous processing, message queues, third-party API integration, and fault tolerance. It’s a practical problem that mirrors real-world engineering challenges at companies like Meta, Google, or any large-scale platform.
The system needs to accept notification requests, process them, and dispatch them via multiple channels like push notifications (APNS, FCM), SMS (Twilio), and email (SendGrid). It must be resilient to third-party service failures, support scheduling, handle retries, and manage user preferences, making it a comprehensive test of your system design interview skills.
Key Discussion Points
- Requirements & Scale Estimation: Clarify functional requirements (send notifications, schedule delivery, track status) and non-functional ones (high availability, reliability, low latency). Estimate the volume, such as 10 million notifications per hour, to justify choices like using a message queue.
- System Architecture: A robust design involves multiple microservices. An API Gateway receives requests and sends them to a Notification Service. This service validates the request, enriches it with user data, and publishes it to a Message Queue like Kafka or RabbitMQ.
- Decoupled Delivery Services: Downstream, have separate worker services for each channel (Push, SMS, Email). Each service consumes messages from the queue, formats the content using a template system, and communicates with the relevant third-party provider (e.g., APNS, Twilio). This decoupling prevents a single provider's failure from halting the entire system.
- Reliability and Tracking: Discuss implementing a retry mechanism with exponential backoff for failed deliveries. A separate Tracking Service should handle delivery status callbacks from providers to update the notification's state (sent, delivered, failed) in a database.
Pro Tip: A critical component is the Message Queue. It acts as a buffer, decoupling the ingestion of notification requests from the actual sending process. This makes the system resilient to traffic spikes and downstream service failures, ensuring no notification is lost even if a third-party API is temporarily unavailable. Also, mention implementing rate limiting to respect provider limits and avoid being flagged as spam.
9. Design a Distributed File Storage System (like Google Drive or Dropbox)
This question challenges you to build one of the most complex yet common applications used today. Designing a system like Dropbox or Google Drive goes beyond simple storage; it tests your knowledge of data synchronization, conflict resolution, distributed file systems, and large-scale data management. Interviewers use it to gauge your ability to design for reliability, consistency, and efficiency when handling user data.
The core task is to allow users to upload, store, and access files from anywhere, on any device. The system must keep files synchronized in near real-time, manage file versions, handle sharing permissions, and support offline access. It is a write-heavy system during uploads and syncs but must also provide low-latency reads.
Key Discussion Points
- Client-Side Architecture: The design starts on the user's device. A client application must monitor a local folder for changes (create, update, delete). It needs to break large files into smaller, manageable chunks for efficient uploads and downloads.
- Synchronization Service: This is the brain of the operation. The client communicates with a central synchronization service to report changes and receive updates from other clients. This service manages file metadata and coordinates the data transfer process.
- Metadata vs. Block Storage: A crucial design choice is separating metadata (file names, versions, permissions, chunk locations) from the actual file content (the chunks). Metadata can be stored in a scalable SQL or NoSQL database, while the file chunks are stored in a distributed object store like Amazon S3.
- Conflict Resolution: What happens if a user edits the same file on two different offline devices? You must design a strategy for handling conflicts. A common approach is to save both versions and notify the user to resolve the conflict manually (e.g., "Conflicted Copy").
Pro Tip: Discuss advanced optimizations like delta syncing and deduplication. Instead of re-uploading an entire file when only a small part changes, delta sync sends only the modified chunks. Deduplication at the chunk level saves immense storage space by storing a single copy of identical chunks across the entire system.
System Design Interview Questions Comparison
Your Next Step: From Theory to Interview Success
You’ve just navigated the architectural blueprints behind some of the most challenging and common system design interview questions. From designing a nimble URL shortener to a globally scaled video streaming platform, you now have a foundational understanding of the core components, trade-offs, and design patterns that interviewers are looking for. The journey through designing news feeds, chat systems, and distributed caches isn't just an academic exercise; it’s a direct reflection of the real-world problems you will be expected to solve as a senior engineer.
The key takeaway is that there is rarely a single "correct" answer. Instead, success lies in your ability to navigate ambiguity, justify your decisions, and articulate a clear, structured thought process. Remember the recurring themes we explored:
- Scalability: Always start with a simple design and discuss how to scale it horizontally and vertically.
- Availability and Reliability: Incorporate redundancy, load balancing, and failover mechanisms from the start.
- Latency: Understand the bottlenecks and employ strategies like caching, CDNs, and choosing the right database to optimize for speed.
- Trade-offs: Every decision, from a database choice to a consistency model, has consequences. Your ability to weigh these pros and cons is what truly demonstrates seniority.
Turning Knowledge into Confidence
Reading about these systems is the first step, but the real test is applying this knowledge under pressure. The gap between knowing the theory of CAP theorem and explaining its implications for a specific database choice in a live interview can be significant. This is where deliberate, targeted practice becomes your greatest asset.
Start by whiteboarding these problems on your own. Talk through your design out loud, as if you were explaining it to an interviewer. This helps solidify the concepts and reveals gaps in your understanding. Consider how the context might change if the interview is for a remote position. The ability to communicate complex technical ideas clearly over video is a critical skill, so be sure to also review common remote job interview questions that often arise in the virtual hiring process.
Ultimately, your goal is to build muscle memory not just for the technical solutions, but for the communication framework itself. You want to walk into that room, virtual or physical, with a clear plan for how to tackle any open-ended design prompt thrown your way. By combining the deep architectural knowledge from this guide with consistent, focused practice, you transform preparation from a chore into a source of confidence. You aren't just memorizing answers; you are becoming the engineer who can build the future.
Ready to bridge the gap between theory and interview-ready performance? AIApply provides a realistic practice environment where you can articulate your designs and receive instant, AI-powered feedback on your communication and technical clarity. Perfect your pitch and build the confidence to ace your next system design interview with AIApply.



Don't miss out on
your next opportunity.
Create and send applications in seconds, not hours.



